// 1 dim
intthreadsPerBlock=256;intblocksPerGrid=(N+threadsPerBlock-1)/threadsPerBlock;kernel<<<blocksPerGrid,threadsPerBlock>>>(...);//2 dim
dim3block(16,16);// 256 threads
dim3grid((width+block.x-1)/block.x,(height+block.y-1)/block.y);kernel<<<grid,block>>>(...);
__device__voidto_index(intordinal,constint*shape,int*out_index,intnum_dims){/**
* Convert an ordinal to an index in the shape. Should ensure that enumerating position 0 ... size of
* a tensor produces every index exactly once. It may not be the inverse of index_to_position.
* Args:
* ordinal: ordinal position to convert
* shape: tensor shape
* out_index: return index corresponding to position
* num_dims: number of dimensions in the tensor
*
* Returns:
* None (Fills in out_index)
*/intcur_ord=ordinal;for(inti=num_dims-1;i>=0;--i){intsh=shape[i];out_index[i]=cur_ord%sh;cur_ord/=sh;}}
__device__intindex_to_position(constint*index,constint*strides,intnum_dims){/**
* Converts a multidimensional tensor index into a single-dimensional position in storage
* based on strides.
* Args:
* index: index tuple of ints
* strides: tensor strides
* num_dims: number of dimensions in the tensor, e.g. shape/strides of [2, 3, 4] has 3 dimensions
*
* Returns:
* int - position in storage
*/intposition=0;for(inti=0;i<num_dims;++i){position+=index[i]*strides[i];}returnposition;}
__device__voidbroadcast_index(constint*big_index,constint*big_shape,constint*shape,int*out_index,intnum_dims_big,intnum_dims){/**
* Convert a big_index into big_shape to a smaller out_index into shape following broadcasting rules.
* In this case it may be larger or with more dimensions than the shape given.
* Additional dimensions may need to be mapped to 0 or removed.
*
* Args:
* big_index: multidimensional index of bigger tensor
* big_shape: tensor shape of bigger tensor
* shape: tensor shape of smaller tensor
* nums_big_dims: number of dimensions in bigger tensor
* out_index: multidimensional index of smaller tensor
* nums_big_dims: number of dimensions in bigger tensor
* num_dims: number of dimensions in smaller tensor
*
* Returns:
* None (Fills in out_index)
*/for(inti=0;i<num_dims;++i){if(shape[i]>1){out_index[i]=big_index[i+(num_dims_big-num_dims)];}else{out_index[i]=0;}}}
__global__voidmapKernel(float*out,int*out_shape,int*out_strides,intout_size,float*in_storage,int*in_shape,int*in_strides,intshape_size,intfn_id){/**
* Map function. Apply a unary function to each element of the input array and store the result in the output array.
* Optimization: Parallelize over the elements of the output array.
*
* You may find the following functions useful:
* - index_to_position: converts an index to a position in a compact array
* - to_index: converts a position to an index in a multidimensional array
* - broadcast_index: converts an index in a smaller array to an index in a larger array
*
* Args:
* out: compact 1D array of size out_size to write the output to
* out_shape: shape of the output array
* out_strides: strides of the output array
* out_size: size of the output array
* in_storage: compact 1D array of size in_size
* in_shape: shape of the input array
* in_strides: strides of the input array
* shape_size: number of dimensions in the input and output arrays, assume dimensions are the same
* fn_id: id of the function to apply to each element of the input array
*
* Returns:
* None (Fills in out array)
*/intout_index[MAX_DIMS];intin_index[MAX_DIMS];intglobal_id=blockIdx.x*blockDim.x+threadIdx.x;// 计算这个 thread 的 global id,对应的就是 out 中的元素位置。注意 out 是实际存储的数组,是一维的
// 排除多余的 threads
if(global_id>=out_size)return;to_index(global_id,out_shape,out_index,shape_size);// 将 1 dim 映射到 2dim
broadcast_index(out_index,out_shape,in_shape,in_index,shape_size,shape_size);// 广播一下, in_index 就是我们要从输入数组中找的位置,是一个 二维的位置
intin_pos=index_to_position(in_index,in_strides,shape_size);// 实际输入的 1 dim 中的位置
intout_pos=index_to_position(out_index,out_strides,shape_size);// 实际输出的 1 dim 中的位置
out[out_pos]=fn(fn_id,in_storage[in_pos]);}
__global__voidzipKernel(float*out,int*out_shape,int*out_strides,intout_size,intout_shape_size,float*a_storage,int*a_shape,int*a_strides,inta_shape_size,float*b_storage,int*b_shape,int*b_strides,intb_shape_size,intfn_id){/**
* Zip function. Apply a binary function to elements of the input array a & b and store the result in the output array.
* Optimization: Parallelize over the elements of the output array.
*
* You may find the following functions useful:
* - index_to_position: converts an index to a position in a compact array
* - to_index: converts a position to an index in a multidimensional array
* - broadcast_index: converts an index in a smaller array to an index in a larger array
*
* Args:
* out: compact 1D array of size out_size to write the output to
* out_shape: shape of the output array
* out_strides: strides of the output array
* out_size: size of the output array
* out_shape_size: number of dimensions in the output array
* a_storage: compact 1D array of size in_size
* a_shape: shape of the input array
* a_strides: strides of the input array
* a_shape_size: number of dimensions in the input array
* b_storage: compact 1D array of size in_size
* b_shape: shape of the input array
* b_strides: strides of the input array
* b_shape_size: number of dimensions in the input array
* fn_id: id of the function to apply to each element of the a & b array
*
*
* Returns:
* None (Fills in out array)
*/intout_index[MAX_DIMS];inta_index[MAX_DIMS];intb_index[MAX_DIMS];intglobal_id=blockIdx.x*blockDim.x+threadIdx.x;if(global_id>=out_size)return;to_index(global_id,out_shape,out_index,out_shape_size);broadcast_index(out_index,out_shape,a_shape,a_index,out_shape_size,a_shape_size);// 计算输入位置
broadcast_index(out_index,out_shape,b_shape,b_index,out_shape_size,b_shape_size);// 计算输入位置
inta_pos=index_to_position(a_index,a_strides,a_shape_size);// 实际输入的 1 dim 中的位置
intb_pos=index_to_position(b_index,b_strides,b_shape_size);// 实际输入的 1 dim 中的位置
intout_pos=index_to_position(out_index,out_strides,out_shape_size);// 实际输出的 1 dim 中的位置
out[out_pos]=fn(fn_id,a_storage[a_pos],b_storage[b_pos]);}
__global__voidreduceKernel(float*out,int*out_shape,int*out_strides,intout_size,float*a_storage,int*a_shape,int*a_strides,intreduce_dim,floatreduce_value,intshape_size,intfn_id){/**
* Reduce function. Apply a reduce function to elements of the input array a and store the result in the output array.
* Optimization:
* Parallelize over the reduction operation. Each kernel performs one reduction.
* e.g. a = [[1, 2, 3], [4, 5, 6]], kernel0 computes reduce([1, 2, 3]), kernel1 computes reduce([4, 5, 6]).
*
* You may find the following functions useful:
* - index_to_position: converts an index to a position in a compact array
* - to_index: converts a position to an index in a multidimensional array
*
* Args:
* out: compact 1D array of size out_size to write the output to
* out_shape: shape of the output array
* out_strides: strides of the output array
* out_size: size of the output array
* a_storage: compact 1D array of size in_size
* a_shape: shape of the input array
* a_strides: strides of the input array
* reduce_dim: dimension to reduce on
* reduce_value: initial value for the reduction
* shape_size: number of dimensions in the input & output array, assert dimensions are the same
* fn_id: id of the reduce function, currently only support add, multiply, and max
*
*
* Returns:
* None (Fills in out array)
*/__shared__doublecache[BLOCK_DIM];// Uncomment this line if you want to use shared memory to store partial results
intout_index[MAX_DIMS];intglobal_id=blockDim.x*blockIdx.x+threadIdx.x;if(global_id>=out_size){return;}to_index(global_id,out_shape,out_index,shape_size);intout_pos=index_to_position(out_index,out_strides,shape_size);intreduce_size=a_shape[reduce_dim];for(inti=0;i<reduce_size;++i){out_index[reduce_dim]=i;inta_pos=index_to_position(out_index,a_strides,shape_size);reduce_value=fn(fn_id,reduce_value,a_storage[a_pos]);}out[out_pos]=reduce_value;}
__global__voidreduceKernel(float*out,int*out_shape,int*out_strides,intout_size,float*a_storage,int*a_shape,int*a_strides,intreduce_dim,floatreduce_value,intshape_size,intfn_id){/**
* Reduce function. Apply a reduce function to elements of the input array a and store the result in the output array.
* Optimization:
* Parallelize over the reduction operation. Each kernel performs one reduction.
* e.g. a = [[1, 2, 3], [4, 5, 6]], kernel0 computes reduce([1, 2, 3]), kernel1 computes reduce([4, 5, 6]).
*
* You may find the following functions useful:
* - index_to_position: converts an index to a position in a compact array
* - to_index: converts a position to an index in a multidimensional array
*
* Args:
* out: compact 1D array of size out_size to write the output to
* out_shape: shape of the output array
* out_strides: strides of the output array
* out_size: size of the output array
* a_storage: compact 1D array of size in_size
* a_shape: shape of the input array
* a_strides: strides of the input array
* reduce_dim: dimension to reduce on
* reduce_value: initial value for the reduction
* shape_size: number of dimensions in the input & output array, assert dimensions are the same
* fn_id: id of the reduce function, currently only support add, multiply, and max
*
*
* Returns:
* None (Fills in out array)
*/__shared__doublecache[BLOCK_DIM];intout_index[MAX_DIMS];inttid=threadIdx.x;intout_id=blockIdx.x;if(out_id>=out_size)return;//out pos
to_index(out_id,out_shape,out_index,shape_size);intout_pos=index_to_position(out_index,out_strides,shape_size);intreduce_size=a_shape[reduce_dim];// the number of threads in a block is restricted to 32. Therefore,
// we have to add some elements before thread-level parallelization.
// We are doing this because the tid will be exploited if a_shape[reduce_dim]
// is greater than blockDim.
floatlocal_acc=reduce_value;for(inti=tid;i<reduce_size;i+=blockDim.x){out_index[reduce_dim]=i;inta_pos=index_to_position(out_index,a_strides,shape_size);local_acc=fn(fn_id,local_acc,a_storage[a_pos]);}cache[tid]=local_acc;__syncthreads();// 等待所有元素在 shared memory 中加载好
for(ints=1;s<blockDim.x;s*=2){if(tid%(2*s)==0){cache[tid]=fn(fn_id,cache[tid],cache[tid+s]);}__syncthreads();// 等待这一层 (step) 的所有 thread 操作完毕
}if(tid==0){out[out_pos]=cache[tid];// 第一个元素就是最后的答案
}}
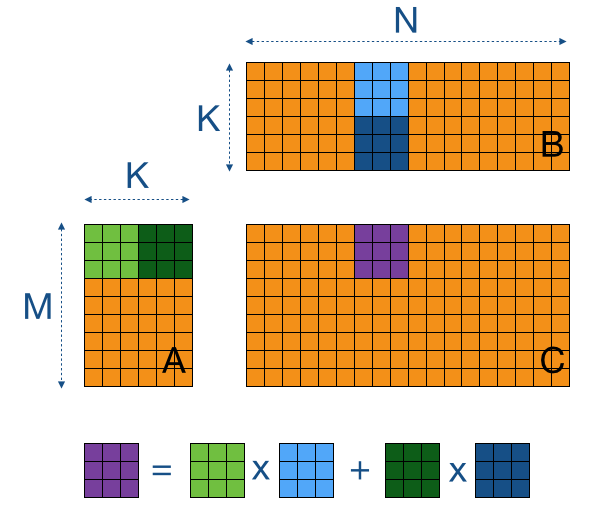
例子 4: MatrixMultiplyKernel:
这里我们跳过 一个 thread 负责一个 out 位置 的写法,直接实现 Tiling 的矩阵乘法。传统写法里边,输出矩阵 C 的一个 out 的位置对应的是输入矩阵 A 的一行,以及输入矩阵 B 的一列。那么传统的写法里边就是:一个 thread 负责一个 C 矩阵的位置,找到输入矩阵 A 和 B 对应的行和列,串行乘积累积和。但是每次 kernel 想要加载行列到 SM 的时候,其实是在访问 global_memory,并且由于每一行和列都要计算多次,实际上需要多次从 global_memory 中加载对应的行列,造成时间浪费。
__global__voidMatrixMultiplyKernel(float*out,constint*out_shape,constint*out_strides,float*a_storage,constint*a_shape,constint*a_strides,float*b_storage,constint*b_shape,constint*b_strides){/**
* Multiply two (compact) matrices into an output (also comapct) matrix. Matrix a and b are both in a batch
* format, with shape [batch_size, m, n], [batch_size, n, p].
* Requirements:
* - All data must be first moved to shared memory.
* - Only read each cell in a and b once.
* - Only write to global memory once per kernel.
* There is guarantee that a_shape[0] == b_shape[0], a_shape[2] == b_shape[1],
* and out_shape[0] == a_shape[0], out_shape[1] == b_shape[1]
*
* Args:
* out: compact 1D array of size batch_size x m x p to write the output to
* out_shape: shape of the output array
* out_strides: strides of the output array
* a_storage: compact 1D array of size batch_size x m x n
* a_shape: shape of the a array
* a_strides: strides of the a array
* b_storage: compact 1D array of size batch_size x n x p
* b_shape: shape of the b array
* b_strides: strides of the b array
*
* Returns:
* None (Fills in out array)
*/__shared__floata_shared[TILE][TILE];// TILE == 32
__shared__floatb_shared[TILE][TILE];intbatch=blockIdx.z;inta_batch_stride=a_shape[0]>1?a_strides[0]:0;intb_batch_stride=b_shape[0]>1?b_strides[0]:0;intm=a_shape[1];intn=a_shape[2];intp=b_shape[2];introw=blockIdx.x*TILE+threadIdx.x;intcol=blockIdx.y*TILE+threadIdx.y;inta_index[3]={batch,row,0};intb_index[3]={batch,0,col};inta_pos;intb_pos;floatacc=0.0f;inta_strides_local[3]={a_batch_stride,a_strides[1],a_strides[2]};intb_strides_local[3]={b_batch_stride,b_strides[1],b_strides[2]};intnum_tiles=(n+TILE-1)/TILE;for(inti=0;i<num_tiles;++i){// load elements for A and B
inta_col=i*TILE+threadIdx.y;a_index[2]=a_col;if(row<m&&a_col<n){a_pos=index_to_position(a_index,a_strides_local,3);a_shared[threadIdx.x][threadIdx.y]=a_storage[a_pos];}else{a_shared[threadIdx.x][threadIdx.y]=0.0f;}intb_row=i*TILE+threadIdx.x;b_index[1]=b_row;if(b_row<n&&col<p){b_pos=index_to_position(b_index,b_strides_local,3);b_shared[threadIdx.x][threadIdx.y]=b_storage[b_pos];}else{b_shared[threadIdx.x][threadIdx.y]=0.0f;}__syncthreads();// Calculation for C
for(intk=0;k<TILE;++k){acc+=a_shared[threadIdx.x][k]*b_shared[k][threadIdx.y];}__syncthreads();}if(row<m&&col<p){intout_index[3]={batch,row,col};intout_pos=index_to_position(out_index,out_strides,3);out[out_pos]=acc;}}
这里有几个小点需要注意一下:
num_tiles 的计算:我们其实要计算的应该是 $\lceil K / TILE \rceil$ 由于 C++ 是下取整,我们可以进行等价变形: $\lceil K / TILE \rceil = \lfloor (K + TILE - 1) / TILE \rfloor$